Welcome back from the holidays! To start your year off right, here's a list of some really cool improvements we've made over the last 2 months or so in E6, our Xinet interface. We're focusing on usability, performance, and generally easing the adoption of using a DAM system, both for casual and power users.
In no particular order, here's what we've been up to-
We released a new theme- 'Air'. It allows a single background image across all pages, custom volume and folder icons, and lots of other neat features. Check it out:
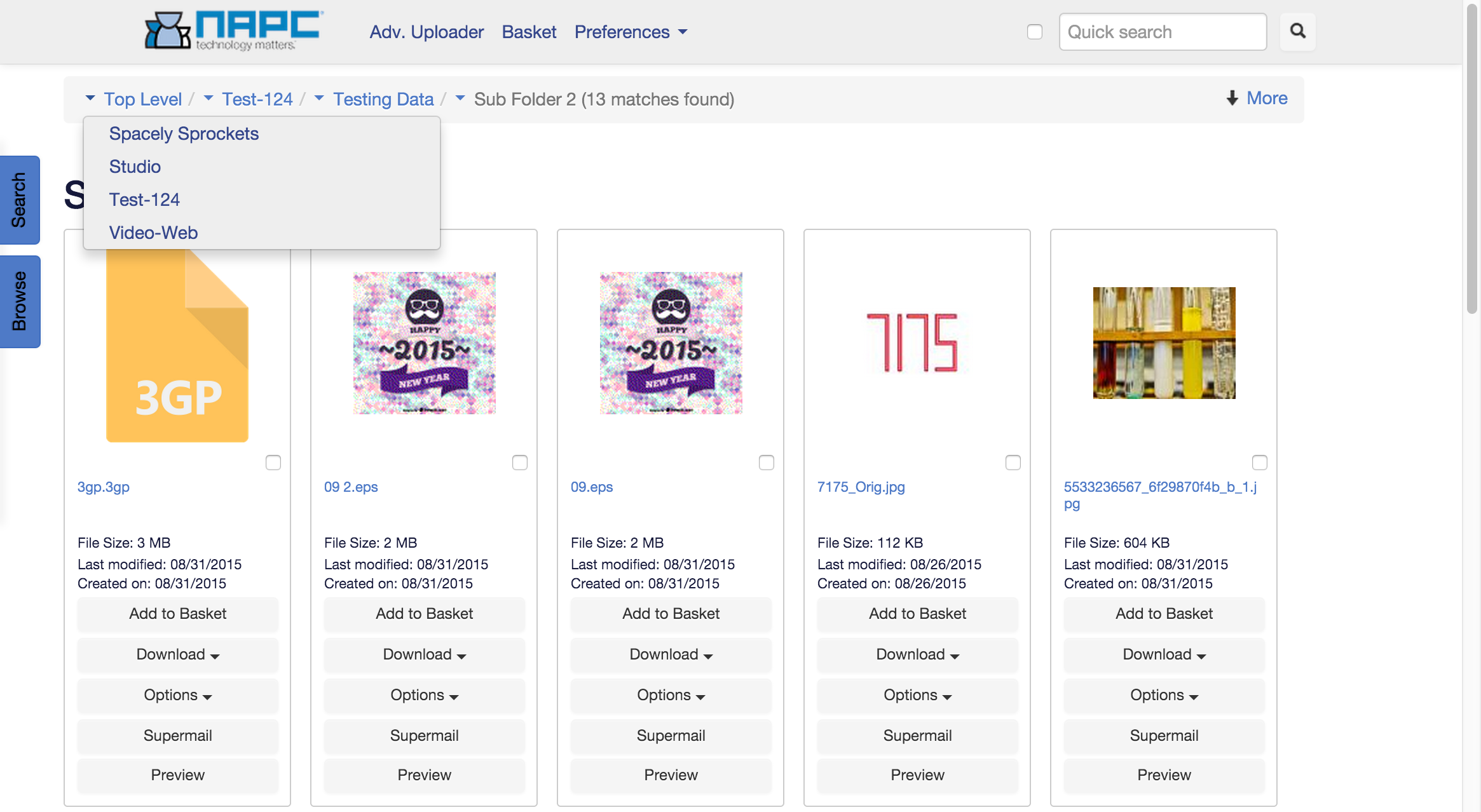
New 'uploader' plugin- a really nice interface for editing metadata on lots of files. It does drag and drop, and drag and select to choose the files you want some metadata applied to, etc... We'll port the code to Batch Keyword Apply in the next couple weeks, so your cybrarians will have a *much* easier time of setting and correcting metadata on groups of files. And of course, we kept the best bits from the original version- individual progress bars, feedback to the users.
'Steal a Link' in SuperMail- both when browsing in E6 and from the Mac desktop. You can now get a SM link copied to your clipboard to add into a personal email. We had lots of folks who didn't want to send a SM to themselves, then copy the link from there into their email client.
New versions comparison function- you can compare 2 files side by side and zoom in on them. Choose different versions of the same file, (even if the filetpes are different!) and compare them.
You can now export and Import E6 sites- Host to host, or on the same host. We had someone build a site on a Dev server in Cali, export it, and import it into the Prod server in Chicago. Cool stuff!
Gallery view- who doesn't love themselves a Gallery? We then added drag&drop to it, because well, drag&drop.
E6 AFR with SuperMail- with fine grained permission rights. It's awesome - reusing the SuperMail interface, it's 100% reliable (a marked improvement over the OOB experience). Check out Sully's video here: bit.ly/E6_AFR
True SSO- we built a SAML plugin for E6 that will work with any idP out there that 'speaks' SAML 2. It just works, as I like to say.
Better Navigation- We're always looking for how to bump productivity and ease of use. We added in the ability to navigate up through higher levels using the breadcrumbs along the top. Little triangles of joy I call them. The developers try and tell me stuff like "it's built with AJAX, so no page load hit", but I just nod my head and enjoy the experience.
Internationalization- It's a global world, and people want a familiar touch. We fully support any and all date formats automatically, based on your browser's settings. If you're in the US, you see month/day/year. If you're in Europe, day/month/year. Text is easily customised too, everything can be translated usng a simple text file.
InPress plugins compatibilty- We wrote E6 with an eye towards openness and ease of integration. All InPress plugins are fully compatible with E6, as are all WebNative Basket plugins.
Documentation- We're documenting everything on our online docs, usually the same day a new feature get's released. Click the help button on any page, and you go right to the correct help page for that subject.
So, start the new year off right, and push that 'update' button in Elegant6. Or, jump the E6 install line by dropping us a line - helpdesk@napc.com . Make the subject "E6 install" or "I need me some E6" (fastest response for that one), and the installation elves will get cracking.
Make your users happy. Make your work life better. E6.

